Indian Journal of Science and Technology
DOI: 10.17485/IJST/v13i46.1660
Year: 2020, Volume: 13, Issue: 46, Pages: 4573-4578
Original Article
Kaushik Kishore Phukon1*
1Pandit Deendayal Upadhyaya Adarsha Mahavidyalaya, Gauhati University, Bongaigaon, 783383, Assam, India. Tel.: 917002551636
*Corresponding Author
Tel: 917002551636
Email: [email protected]
Received Date:13 September 2020, Accepted Date:07 December 2020, Published Date:19 December 2020
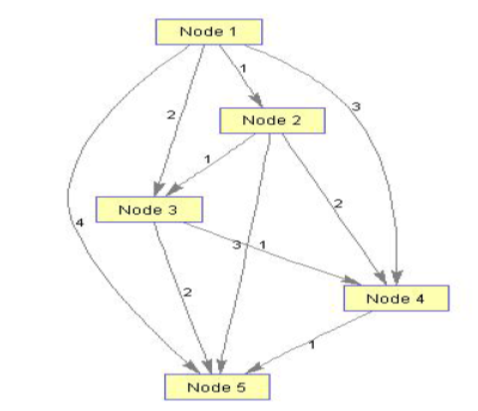
Objectives: The objectives of this research article is to deal with the problem of web document clustering by modeling the web documents as directed completely labeled graphs that incorporate contextual information in the computation process to the extent required. The computational complexity of the MCS algorithm based on this graph model is O(n2), n being the number of nodes. As graph similarity using MCS is an NP-complete problem, so this is an important result that allows us to forgo sub-optimal approximation approaches and find the exact solution in polynomial time. Method: The first step towards this new approach of web document clustering is the representation of the web documents with the help of a directed completely labeled graph that can retain contextual information of the document under consideration. After graphical modeling of the document, the next step is the calculation of similarity between the graphical objects. For this purpose, a customized algorithm proposed as Algorithm for Maximum Common Subgraph Isomorphism (AMCSI)(1) based on a backtracking search scheme is being used. The proposed AMCSI algorithm is solving the problem of maximum common subgraph isomorphism in polynomial time. After obtaining the value for the similarity between the graphical objects we are again using a customized fuzzy-c means algorithm to produce clusters from the target set of web documents. We are using multidimensional scaling to express the distance values between the web pages (graphs) in two coordinates (x,y) and deterministic sampling to calculate the graph median in the process of fuzzy c-means clustering. Findings: We present an alternative method for web document clustering by representing the web documents as directed completely labeled graphs where the computational complexity of the MCS algorithm is O(n2)(1). A new distance measure is also developed based on the directed completely labeledgraph representation which is giving 16.9% better result than the prevailing methods(2). For the clustering purpose, we have chosen the fuzzy cmeans clustering algorithm and customizing the original algorithm to fit with graphical objects. This approach enables us to model the web documents as graphs without discarding contextual information and then cluster these graphical objects with the help of a well-established clustering algorithm.
Keywords: Vector; graph; web document; subgraph; isomorphism; fuzzy; clustering
© 2020 Phukon.This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.