Indian Journal of Science and Technology
Year: 2022, Volume: 15, Issue: 1, Pages: 19-27
Original Article
Mezgebe Araya1, Minyechil Alehegn1*
1School of Computing and Informatics, Mizan Tepi University, Ethiopia
*Corresponding Author
Email: [email protected]
Received Date:13 November 2021, Accepted Date:30 December 2021, Published Date:21 January 2022
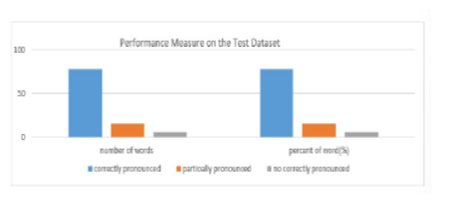
Objectives: The purpose of this study is to describe text-to-speech system for the Tigrigna language, using dialog fusion architecture and developing a prototype text-to-speech synthesizer for Tigrigna Language. Methods : The direct observation and review of articles are applied in this research paper to identify the whole strings which are represented the language. Tools used in this work are Mathlab, LPC, and python. In this paper LSTM deep learning model was applied to find out accuracy, precision, recall, and Fscore. Findings: The overall performance of the system in the word level which is evaluated by NeoSpeech tool is found to be 78% which is fruitful. When it comes to the intelligibility and naturalness of the synthesized speech in the sentence level, it is measured in MOS scale and the overall intelligibility and naturalness of the system are found to be 3.28 and 3.27 respectively. Based on the experiment LSTM Deep learning model provides an accuracy of 91.05%, the precision of 78.05%, recall of 86.59 %, and F-score of 83.05% respectively. The values of performance, intelligibility, and naturalness are inspiring and show that diphone speech units are good candidates to develop a fully functional speech synthesizer. Novelty: The researchers come up with the first text to speech LSTM deep learning model for the Tigrigna language which is critical and will be a baseline for other related research to be done for Tigrigna and other languages.
Keywords: LSTM; speech synthesis; Tigrigna syllables; TexttoSpeech; Concatenative approach
© 2022 Araya & Alehegn. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.