Indian Journal of Science and Technology
DOI: 10.17485/IJST/v13i44.1479
Year: 2020, Volume: 13, Issue: 44, Pages: 4474-4482
Original Article
Vasantha Kumari Garbhapu1*, Prajna Bodapati2
1Research Scholar, Department of Computer Science and Systems Engineering, Andhra University College of Engineering, Visakhapatnam, A.P, India
2Professor, Department of Computer Science and Systems Engineering, Andhra University College of Engineering, Visakhapatnam, 530003, A.P, India
*Corresponding Author
Email: [email protected]
Received Date:20 August 2020, Accepted Date:03 December 2020, Published Date:13 December 2020
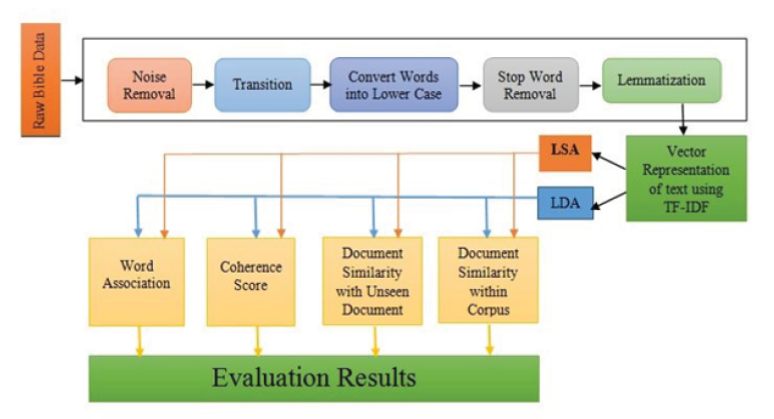
Objective: To compare the topic modeling techniques, as no free lunch theorem states that under a uniform distribution over search problems, all machine learning algorithms perform equally. Hence, here, we compare Latent Semantic Analysis (LSA) or Latent Dirichlet Allocation (LDA) to identify better performer for English bible data set which has not been studied yet. Methods: This comparative study divided into three levels: In the first level, bible data was extracted from the sources and preprocessed to remove the words and characters which were not useful to obtain the semantic structures or necessary patterns to make the meaningful corpus. In the second level, the preprocessed data were converted into a bag of words and numerical statistic TF-IDF (Term Frequency – Inverse Document Frequency) is used to assess how relevant a word is to a document in a corpus. In the third level, Latent Semantic analysis and Latent Dirichlet Allocations methods were applied over the resultant corpus to study the feasibility of the techniques. Findings: Based on our evaluation, we observed that the LDA achieves 60 to 75% superior performance when compared to LSA using document similarity within-corpus, document similarity with the unseen document. Additionally, LDA showed better coherence score (0.58018) than LSA (0.50395). Moreover, when compared to any word within-corpus, the word association showed better results with LDA. Some words have homonyms based on the context; for example, in the bible; bear has a meaning of punishment and birth. In our study, LDA word association results are almost near to human word associations when compared to LSA. Novelty: LDA was found to be the computationally efficient and interpretable method in adopting the English Bible dataset of New International Version that was not yet created.
Keywords: Topic modeling; LSA; LDA; word association; document similarity;Bible data set
© 2020 Garbhapu & Bodapati.This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.