Indian Journal of Science and Technology
DOI: 10.17485/IJST/v14i40.1279
Year: 2021, Volume: 14, Issue: 40, Pages: 3026-3050
Review Article
Ankita Chadha1,*, Azween Abdullah2, Lorita Angeline2, Sivakumar Sivanesan2
1 Doctorate Student, School of Computer Science and Engineering, Taylors University, 47500, Selangor, Malaysia
2 School of Computer Science and Engineering, Taylors University, 47500, Selangor, Malaysia
*Corresponding author email: [email protected]
Received Date:09 July 2021, Accepted Date:19 October 2021, Published Date:29 November 2021
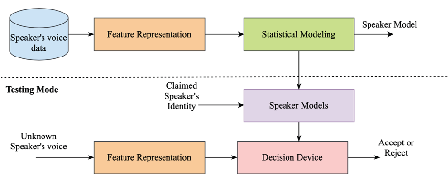
Background/Objectives: The anti-spoofing measures are blooming with an aim to protect the Automatic Speaker Verification systems from susceptible spoofing attacks. This review is an amalgam of the possible attack types, the datasets required, the renowned feature representation techniques, modeling algorithms involving machine learning, and score normalization techniques. Method/Findings: A detailed analysis of existing datasets is carried based on the total speaker samples, the number of speakers, and source of availability- open or licensed. This may foster choosing the right dataset for building the anti-spoofing frameworks. Further, the feature extraction schemes are elaborated with an intention to cover the vast span of features existing in various parts of raw speech for obtaining speaker-specific traits. Further, the machine learning algorithms ranging from discriminative to generative to mixed form are explored for seeking the right algorithm in specific attack conditions. On the whole, these analyses of existing features and machine learning algorithms together contribute to classifying the unknown test samples as genuine or spoofed. The score normalization techniques are also considered in this review to avoid any misclassifications and ultimately reduce the False Acceptance Ratios. The performance of any anti-spoofing speaker verification system may be evaluated using standard objective measures such are Equal Error Rate, False positive ratios, and graphical plots. These measures are briefly explained in this review. Overall, the critical analysis of individual methods-feature extraction, machine learning, score normalization, and all the anti-spoofing datasets are also discussed for giving a kick-start to any researcher beginning to explore in this direction. The shortcomings and risks involved in building an enhanced speaker verification system that is robust to almost all the attack types are listed in this article. The review of studies conducted so far has led to vital future directions that are enlisted in the concluding remarks of the article.
Keywords: Automatic Speaker Verification; Spoofed Detection, AntiSpoofing, Voice Conversion, Speech Synthesis, Replay Speech
© 2021 Chadha et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.




