Indian Journal of Science and Technology
DOI: 10.17485/IJST/v17i15.2979
Year: 2024, Volume: 17, Issue: 15, Pages: 1545-1556
Original Article
Pramod P Ghogare1*, Husain H Dawoodi2, Manoj P Patil3
1Research Scholar, School of Computer Sciences, Kavayitri Bahinabai Chaudhari North Maharashtra University, Jalgaon, Maharashtra, India
2System Analyst, School of Computer Sciences, Kavayitri Bahinabai Chaudhari North Maharashtra University, Jalgaon, Maharashtra, India
3Assistant Professor, School of Computer Sciences, Kavayitri Bahinabai Chaudhari North Maharashtra University, Jalgaon, Maharashtra, India
*Corresponding Author
Email: [email protected]
Received Date:22 November 2023, Accepted Date:06 March 2024, Published Date:12 April 2024
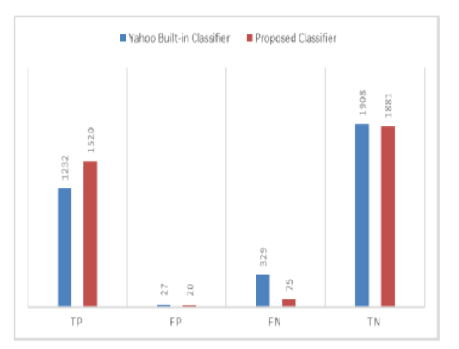
Objective: This article proposes a content-based spam email classification by applying various text pre-processing techniques. NLP techniques have been applied to pre-process the content of an email to get the optimal performance of spam email classification using machine learning. Method: Several combinations of pre-processing methods, such as stopping, removing tags, converting to lower case, removing punctuation, removing special characters, and natural language processing, were applied to the extracted content from the email with machine learning algorithms like NB, SVM, and RF to classify an email as ham or spam. The standard datasets like Enron and SpamAssassin, along with the personal email dataset collected from Yahoo Mail, are used to evaluate the performance of the models. Findings: Applying stemming in pre-processing to the RF classifier yielded the best results, achieving 99.2% accuracy on the SpamAssassin dataset and 99.3% accuracy on the Enron dataset. Lemmatization followed closely with 99% accuracy. In real-world testing on a personal Yahoo email dataset, the proposed method significantly improved accuracy from 89.82% to 97.28% compared to the email service provider's built-in classifier. Additionally, the study found that SVM performs accurately when stop words are retained. Novelty: This article introduces a unique perspective by highlighting the fine-tuning of pre-processing techniques. The focus is on removing tags and certain special characters, while retaining those that improve spam email classification accuracy. Unlike prior works that primarily emphasize algorithmic approaches and pre-defined processing functions, our research delves into the intricacies of data preparation, showcasing its significant impact on spam email classifiers. These findings emphasize the crucial role of pre-processing and contribute to a more nuanced understanding of effective strategies for robust spam detection.
Keywords: Spam, Classification, Pre-processing, NLP, Machine Learning
© 2024 Ghogare et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.