Indian Journal of Science and Technology
Year: 2023, Volume: 16, Issue: 12, Pages: 924-930
Original Article
Irum Naz Sodhar1*, Suriani Sulaiman2, Abdul Hafeez Buller3
1Post-Doctoral Fellow, Department of Computer Science, Kulliyyah (Faculty) of Information and Communication Technology, International Islamic University, Malaysia
2Assistant Professor, Department of Computer Science, Kulliyyah (Faculty) of Information
and Communication Technology, International Islamic University, Malaysia
3Post-Doctoral Fellow, Department of Civil Engineering, Kulliyyah (Faculty) of Engineering, International Islamic University, Malaysia
*Corresponding Author
Email: [email protected]
Received Date:01 February 2023, Accepted Date:23 March 2023, Published Date:28 March 2023
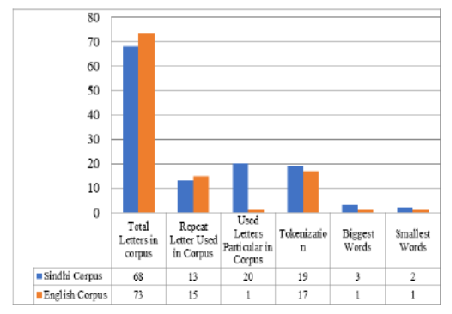
Objectives: The Sindhi language is given more importance in Sindh’s educational institutions than other regional languages, and the majority of the population uses it in today’s mobile programs, letters, text messages and other text conversations. Research is needed to analyze the Sindhi corpus, as communication over computer systems and mobile phones is growing significantly. This research study focuses on the Sindhi alphabet and performs different tasks on the corpus. Methods: Data collection was conducted from available resources, and a corpus was created in Sindhi and English. Twenty patterns of letters are used, three dot alignments are used in the letters, and six symbols are used for making letters. After the collection, data was explored and analyzed with different tasks. Findings: The corpus of Sindhi text is being built due to its importance for language, linguistics and other developments in NLP. This research study focuses on statically analyzing the Sindhi-English corpus through reality basis, finding that there are two small words ( ۽ and ۾) and three biggest words ( پاڪستان, انگلینڊ and ڳالھیون ). The letter ' آ' is used as a single letter in Sindhi alphabets, with the minimum frequently occurring letter being consonant and the maximum frequently being . ئ vowel. Novelty: Text analysis is an important area in data mining and in other research, and this research study focuses on statically analyzing the Sindhi-English corpus through statically on reality basis. The author explores orthography and Sindhi composition of copra, and recommends that the Romanized languages data be used in Sindhi as well. Preprocessing is not easy due to lack of resources, and the character conversion model has generated two languages.
Keywords: Sindhi; Language exploration; Corpus; Statistical Analysis; pattern of letters; Text conversation
© 2023 Sodhar et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.