Indian Journal of Science and Technology
DOI: 10.17485/IJST/v16i30.1523
Year: 2023, Volume: 16, Issue: 30, Pages: 2317-2324
Original Article
K Arul Deepa1*, Shanmuga Priya2, P Velvizhy2
1Dept. of IST, College of Engineering Guindy, Anna University, Chennai
2Dept. of CSE, College of Engineering Guindy, Anna University, Chennai
*Corresponding Author
Email: [email protected]
Received Date:20 June 2023, Accepted Date:28 June 2023, Published Date:08 August 2023
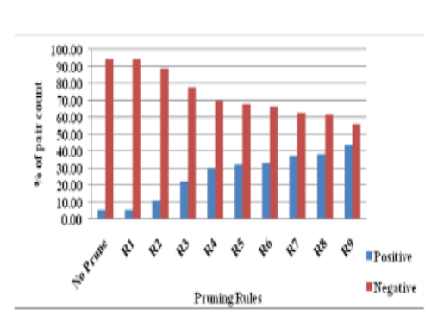
Background: Like many other real world applications, the machine learning system of anaphora resolution also struggles with skewed data. The problem of imbalanced classes occurs with classification task where there a huge difference exists in the number of instances among the involved classes.Objectives: The proposed framework intends to remove the imbalance first between positive and negative class instances before classifying them by KBUS that makes use of cognitive knowledge about the language and analysis is done at attribute level. Method: Nine pruning rules are crafted by KBUS(KNN Based Under Sampling) for TDIL dataset. Findings: During experimentation, number of positive instances are increased from 5.32% to 43.95%, whereas the number of negative instances are decreased from 94.68% to 56.05%. Loss ratio of positive and negative instance is 1:112. Finally the pruned dataset is classified by a list of classifiers namelyNaïve Bayes, SVM, Random forest, decision tree and k-NN. Novelty: Classifier results are discussed in two perspectives: Firstly the number of input instances and secondly the performance improvement achieved after pruning. It is adduced that pruning shows a remarkable improvement for all the classifiers. The proposed system produced an encouraging result as 78% of f-measure for k-NN and 77% for decision tree. Performance is presented in a comparative manner before and after pruning and the improvement of fmeasureranges from 13% (k-NN) to 41% (Random Forest). Thus this work has come up with a machine learning model to resolve Tamil anaphoric situations effectively in an imbalanced classification environment.
Keywords: Imbalanced Dataset; Classification; Anaphora Resolution Machine Learning; Pronominal Reference
© 2023 Deepa et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.