Indian Journal of Science and Technology
DOI: 10.17485/IJST/v14i41.1858
Year: 2021, Volume: 14, Issue: 41, Pages: 3082-3092
Original Article
P S Subhashini Pedalanka1,2*, M SatyaSai Ram3, Duggirala Sreenivasa Rao4
1Associate Professor, Department of E.C.E, R.V.R & JC College of Engineering, Chowdavaram, Guntur, India
2Research scholar, Department of E.C.E, JNTUH, Hyderabad, India
3Professor, Department of E.C.E, R.V.R & JC College of Engineering, Chowdavaram, Guntur, India
4Professor, Department of E.C.E, JNTUH, Hyderabad, India
*Corresponding Author
Email: [email protected]
Received Date:04 October 2021, Accepted Date:18 November 2021, Published Date:04 December 2021
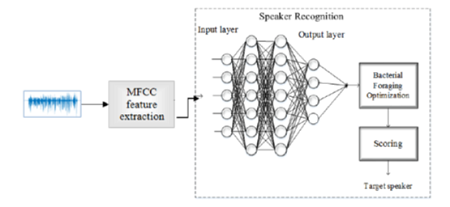
Objectives: To improve the accuracy and to reduce the time complexity of the Speaker Recognition system using Mel-Frequency Cepstral Coefficients (MFCCs) and Bacterial Foraging optimization (BFO) with DNN –RBF. Method: The MFCCs of each speech sample are derived by pre-processing the audio speech signal. The features are optimized with BFO algorithm. Finally, the probability score for each speaker is generated to identify the speaker. Then the features are classified towards the target speaker using DNN-RBF. For the proposed MBFOB speaker recognition function, the TIMIT read corpus is used. It contains a total of 6300 phrases, 10 phrases each. Findings: the identity of user is validated in the fields of authentication and surveillance for recognition of speaker. By using the audio speech signal, features are extracted. This paper suggests an MBFOB solution based on Mel-frequency Cepstral Coefficients and DNN-RBF with BFO, for the identification of speakers. The speech utterance from the TIMIT data corpus is preprocessed to obtain MFCC feature vectors DNN-RBF is used for the purpose of classifying the speaker and the feature vectors in the output layers are optimized with Bacterial Foraging optimization. Finally, the scores for each speaker are calculated to identify the speaker. Different output metrics like EER, DCF, Cavg and accuracy are used to test the proposed speaker recognition technique. The execution time of this proposed method is found to be lesser than the other existing methods. The experimental findings are contrasted with other current methods and it shows the efficiency of our approach. Novelty: A novel MFCC-based Bacterial Foraging Optimization with Deep Neural Network-Radial Basis Function (DNN-RBF) for identification of exact speaker is proposed in this study.
Keywords: BFO; DNN; RBF; Speech processing; speaker recognition; MFCC extraction; deep neural network; and Bacterial foraging optimization; scoring
© 2021 Subhashini Pedalanka et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.