Indian Journal of Science and Technology
DOI: 10.17485/IJST/v13i11.2020-31
Year: 2020, Volume: 13, Issue: 11, Pages: 1276-1282
Original Article
J Ujwala Rekha1*, K Shahu Chatrapati1,2
1Associate Professor of CSE, JNTUH College of Engineering Hyderabad, Telangana, India
2Professor of CSE, JNTUH College of Engineering Manthani, Telangana, India
*Author for correspondence
J Ujwala Rekha
Associate Professor of CSE, JNTUH College of Engineering Hyderabad, Telangana, India
Email: [email protected]
Received Date:29 February 2020, Accepted Date:30 March 2020, Published Date:03 May 2020
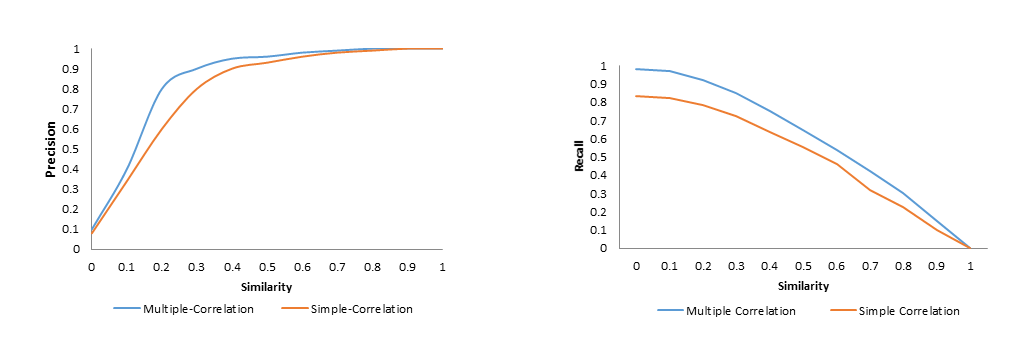
Background/Objectives: In this study, a term weighting scheme derived from probabilistic multiple correlation is defined for measuring similarity between unstructured text records. Methods: While the intra-correlation is the correlation of terms in the same record, inter-correlation is the correlation of terms that exist in different records. Probabilistic multiple correlation-based term weighting calculates the weight or relevance of a term by considering its intra-correlation with one or more terms simultaneously. Subsequently, the term weights are used in measuring the inter-correlation of terms and then the similarity between two text records. Findings: The experiments are run on unstructured text records that are incomplete and employ abbreviations. There is significant improvement in precision, recall and f-score using probabilistic multiple correlation based term weighting scheme when compared with probabilistic simple correlation weighting scheme. Applications: Using probabilistic multiple correlation based term weighting scheme can improve the overall accuracy in matching unstructured text records that contain abbreviations and incomplete data.
Keywords: Unstructured Text; Approximate String Matching; Citation Matching; Probabilistic Correlation; Term Weight; Similarity Measure
Copyright: © 2020 Rekha, Chatrapati. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.