Indian Journal of Science and Technology
DOI: 10.17485/IJST/v15i41.1566
Year: 2022, Volume: 15, Issue: 41, Pages: 2188-2193
Original Article
B L Shilpa1*, B R Shambhavi2
1Assistant Professor, Department of ISE, GSSSIETW, Mysuru, Karnataka, India
2Associate Professor, Department of ISE, BMSCE, Bengaluru, Karnataka, India
*Corresponding Author
Email: [email protected]
Received Date:30 July 2022, Accepted Date:28 September 2022, Published Date:10 November 2022
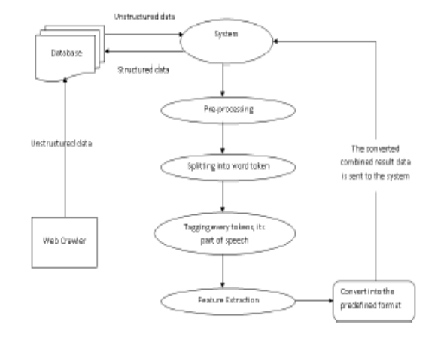
Objectives: To develop a new data gathering processing under Big Data Perspectives. To convert unstructured text data into structured format by not missing out any text data available. Methods: The unstructured data is preprocessed using modified stemming and tokenization. From the stemming output, the proposed Term Frequency-Inverse Document Frequency (TF-IDF) and N-gram features are derived. Unstructured data is considered from multiple sources like twitter, consumer complaints and news blog. Findings: The proposed model with extant TF-IDF features has exposed relatively high Mean Average Error (MAE) value which is 1.4325 when compared to the proposed model without optimization to be 0.5197. Novelty: The novelty of the research work is of the stemming process where dictionary checking process is added and the improved feature extraction, interclass dispersion coefficient is computed in TF-IDF features.
Keywords: Natural language processing; Structured data; Unstructured data; Big data; Feature extraction
© 2022 Shilpa & Shambhavi. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.




