Indian Journal of Science and Technology
DOI: 10.17485/IJST/v14i24.2017
Year: 2021, Volume: 14, Issue: 24, Pages: 2039-2050
Original Article
E Sujatha1*, R Radha2
1Research Scholar, Research Dept of Computer Science, SDNBV College for Women, University of Madras, Chrompet, Chennai, 600 044, India
2Associate Professor, Research Dept of Computer Science, SDNBV College for Women, Chrompet, Chennai, 600 044, India
*Corresponding Author
Email: [email protected]
Received Date:07 December 2020, Accepted Date:05 July 2021, Published Date:15 July 2021
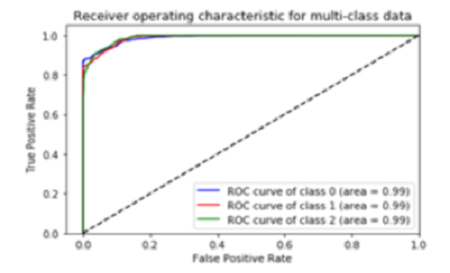
Objectives: Toextract and identify the subjective information of social media user from the unstructured data. To overcome the high dimensionality and sparsity those are the two major challenges in sentiment analysis of text datasets. To increase the model performance by using possibly minimum feature sets in a text classification problem. Methods: We proposed a new filtration method which is applied for the removal of correlated features and zero importance features in addition to the various feature selection methods. The various feature selections such as Mutual Info, Lasso, Recursive Feature Elimination and dimensionality reduction, Principal Component Analysis (PCA) have been used along with the proposed filtration to find the compelling features. This approach was evaluated using three Indian Government Schemes and these tweets were classified using Random Forest classifier. The performance was evaluated using various metrics such as accuracy, precision, recall, f1_score, log loss and roc-auc. Findings: In this research, we proposed a model for selecting relevant and non-correlated feature subsets from the unstructured dataset. From this model, accuracy of 92% with the minimum log loss 0.22 was achieved through the minimum number of feature set. Improvements: This study proves that the performance of the model will be improved by overcoming those two problems (dimensionality and sparsity). Here various feature selection methods have been applied with the proposed filtration in order to minimize the number of features. The computing time and the model performance will be improved as a result of decreasing the features. And this will be more effective in case of large datasets. Even though Random Forest performs well in high dimensional datasets we need some more optimization.
Keywords: Mutual Information (MI); Lasso (L1); Recursive Feature Elimination (RFE); Random Forest (RF); Principal Component Analysis (PCA)
© 2021 Sujatha & Radha. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.