Indian Journal of Science and Technology
DOI: 10.17485/IJST/v13i34.1078
Year: 2020, Volume: 13, Issue: 34, Pages: 3561-3571
Original Article
A Senthilkumar1*, D Hari Prasad2
1Research Scholar, Sri Ramakrishna College of Arts and Science, Coimbatore, 641 006
2Professor and Head, Department of Computer Application, Sri Ramakrishna College of Arts and Science, Coimbatore, 641 006
*Corresponding Author
Email: [email protected]
Received Date:06 July 2020, Accepted Date:05 September 2020, Published Date:22 September 2020
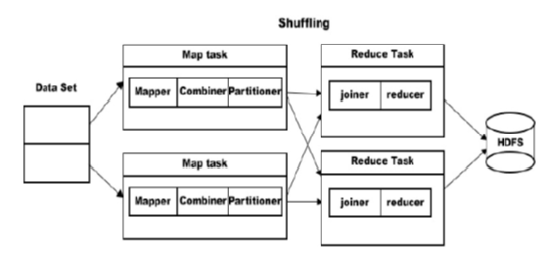
Objectives: To achieve improved performance of FP-Growth based Association Rule Mining algorithm for massive data by effective utilization of storage,execution capability and improved partition technique within the Hadoop MapReduce framework. Methodology: The proposed methodology has four main phases: In the first phase, the item sets for finding the frequent pattern are encoded and thus minimizes the expensive operation for large data set. In the second phase, improved hash partitioning reduces the network overhead and improves the communication speed within the MapReduce phase for each item set. The effective usage of network bandwidth and storage is obtained by the impact of compression in the third phase. The use of combiner in final phase for frequent item set mining minimizes the overhead of reduce phase by finding the pattern in each partition and minimizes the overall execution time of the FP-Growth algorithm. Findings: FP-Growth based association rule mining algorithm is designed for parallel execution on distributed cluster of servers. Changes to the MapReduce implementation of FP-Growth with the impact of encoding. Improved hash partitioning, compression and configuration results in a significant performance gain with better improvement in execution time.Novelty/Improvements: According to the experimental results, the changes in storage and processing level within the MapReduce framework improves the overall performance of the parallel frequent item set mining in Hadoop cluster.
Keywords: Association rule mining; Hadoop; MapReduce; FP-Growth
© 2020 Senthilkumar & Hari Prasad.This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee).
Subscribe now for latest articles and news.