Indian Journal of Science and Technology
DOI: 10.17485/IJST/v16i46.2090
Year: 2023, Volume: 16, Issue: 46, Pages: 4410-4420
Original Article
V K Muneer1*, K P Mohamed Basheer1, Rizwana Kallooravi Thandil1
1Department of Computer Science, Sullamussalam Science College, Affiliated to University of Calicut, Kerala, India
*Corresponding Author
Email: [email protected]
Received Date:17 August 2023, Accepted Date:23 October 2023, Published Date:15 December 2023
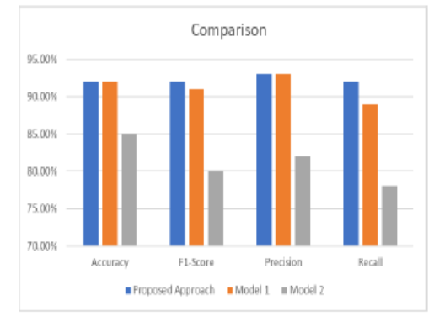
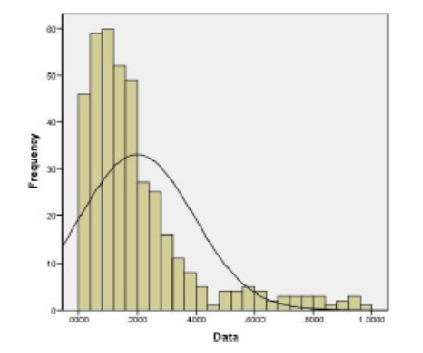
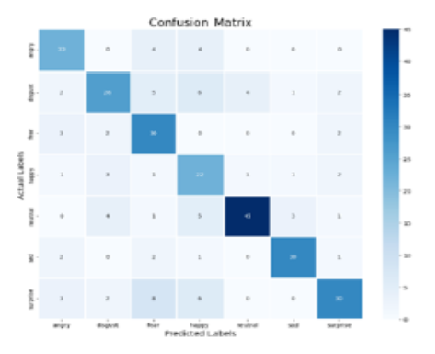
Objectives: This research work focuses on developing a SER system using CNN and deep learning techniques for a low-resourced Dravidian Indian Language, Malayalam. The importance of speech as a powerful and natural medium of communication, capable of conveying a wide range of information about an individual's mental, behavioral, and emotional characteristics. With the increasing prevalence of human-machine interactions, the study of speech analysis has played a crucial role in bridging the gap between the physical and digital realms. Particularly, the field of emotion identification has gained popularity, as emotions are frequently expressed through speech cues. However, the scarcity of suitable datasets poses a challenge for researchers conducting experiments. Methods: In this paper, we address this challenge by employing Long Convolutional Neural Networks (CNN) to effectively recognize sentiments in voice recordings of Malayalam, a low-resource language. We manually construct datasets from audio clips of Malayalam movies and employ the Mel Frequency-Cepstral-Coefficient (MFCC) approach to extract features from the audio signals. Findings: By training, classifying, and testing our model using raw speech data from the dataset, the paper proposes a novel approach for recognizing emotions from voice signals processed in Malayalam with an average accuracy of 71%, indicating its ability to correctly predict emotions from vocal utterances in this under-resourced Language. Novelty: The novelty of this work lies in its dedication to addressing the challenges of emotion recognition in a low-resource language, the manual creation of datasets, and the successful adaptation of established techniques to a linguistic context where research is relatively scarce. These contributions collectively advance the field of speech emotion recognition and pave the way for further exploration in underrepresented languages.
Keywords: Speech emotion recognition, Malayalam, Natural Language Processing, MFCC, CNN
© 2023 Muneer et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.