Indian Journal of Science and Technology
DOI: 10.17485/IJST/v16i41.2128
Year: 2023, Volume: 16, Issue: 41, Pages: 3704-3713
Original Article
Archika Jain1*, Sandhya Sharma2
1Department of CSE, Suresh Gyan Vihar University, 302017, Jaipur, India
2Department of ECE, Suresh Gyan Vihar University, 302017, Jaipur, India
*Corresponding Author
Email: [email protected]
Received Date:22 August 2023, Accepted Date:03 October 2023, Published Date:12 November 2023
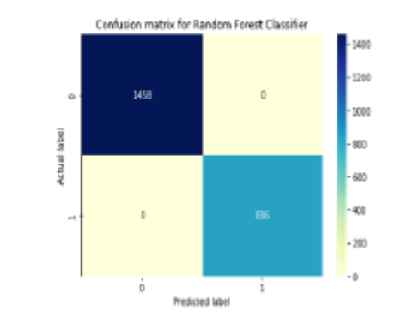
Objectives: To develop an improved hate speech detection method based on word embedding and linguistic features. Methods: Many machine-learning classifiers like Logistic Regression (LR), Gaussian Naive Bayes (GNB), Random Forest (RF), K-Nearest Neighbor (KNN) and Linear Support Vector Classifier (SVC) are trained on linguistic data for identifying hated speech. For this research two datasets has been used with the size of 24783 tweets and 6977 tweets for Tweet hate speech detection dataset and Hasoc19 dataset respectively. We have taken the size of training and testing dataset is 67/33 for both the dataset, in which size of training dataset is 67 and size of testing dataset is 33. Findings: On Tweet hate speech detection dataset we target the highest accuracy 0.90 and highest precision, recall and f1-score like 0.87, 0.85 and 0.90 respectively for label 0 and 0.98, 0.98 and 0.93 respectively for label 1 and 0.86, 0.85 and 0.74 for class 2 after applying random forest classifier. On Hasoc2019 dataset we achieve the highest accuracy 0.99 and highest precision, recall and f1-score values like 1.00, 0.99 and 1.00 for class 0 and 1.0, 0.99 and 0.99 for class 1 after applying Random Forest classifier with linguistic features TF-IDF word embedding technique. Novelty: Twenty linguistic features with term frequency-inverse document frequency (TF-IDF) word embedding technique make this research unique. Twenty linguistic characteristics have been chosen for detecting the despised information based on three groups of attributes which is complexity attributes, stylometric attributes and psycho-linguistic attributes have been chosen.
Keywords: Machine Learning Classifiers, Linguistic Features, Accuracy, TFIDF, Random Forest Classifier
© 2023 Jain & Sharma. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.