Indian Journal of Science and Technology
Year: 2023, Volume: 16, Issue: 4, Pages: 282-291
Original Article
Savitha Murthy1*, Dinkar Sitaram2
1PhD Scholar, Department of CSE, PES University, India
2Director, Cloud Computing Innovation Council of India, India
*Corresponding Author
Email: [email protected]
Received Date:10 December 2022, Accepted Date:05 January 2023, Published Date:31 January 2023
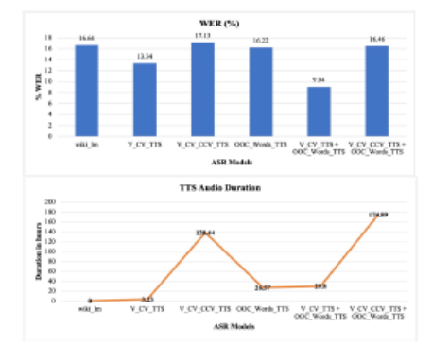
Objectives: Improving the accuracy of low resource speech recognition in a model trained on only 4 hours of transcribed continuous speech in Kannada language, using data augmentation. Methods: Baseline language model is augmented with unigram counts of words, that are present in the Wikipedia text corpus but absent in the baseline, for initial decoding. Lattice rescoring is then applied using the language model augmented with Wikipedia text. Speech synthesis-based augmentation with multi-speaker syllable-based synthesis, using voices in Kannada and cross-lingual Telugu languages, is employed. We synthesize basic syllables, syllables with consonant conjuncts, and words that contain syllables that are absent in the training speech, for Kannada language. Findings: An overall word error rate (WER) of 9.04% is achieved over a baseline WER of 40.93%. Language model augmentation and lattice rescoring gives an absolute improvement of 16.68%. Applying our method of syllable-based speech synthesis over language model augmentation and rescoring yields a total reduction of 31.89% in WER. The proposed approach of language model augmentation is memory efficient and consumes only 1/8th the memory required for decoding with Wikipedia augmented language model (2 gigabytes versus 18 gigabytes) while giving comparable WER (22.95% for Wikipedia versus 24.25% for our method). Augmentation with synthesized syllables enhances the ability of the speech recognition model to recognize basic sounds thus improving recognition of out-of-vocabulary words to 90% and in-vocabulary words to 97%. Novelty: We propose novel methods of language model augmentation and synthesis-based augmentation to achieve low WER for a speech recognition model trained on only 4 hours of continuous speech. Obtaining high recognition accuracy (or low WER) for very small speech corpus is a challenge. In this paper, we demonstrate that high accuracy can be achieved using data augmentation for a small corpus-based speech recognition.
Keywords: Low resource; Speech synthesis; Data augmentation; Language model; Lattice rescoring
© 2023 Murthy & Sitaram. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.