Indian Journal of Science and Technology
Year: 2023, Volume: 16, Issue: 16, Pages: 1214-1220
Original Article
S Karthikeyan1*, T Kathirvalavakumar2
1Research Scholar, Research centre in Computer Science, V.H.N. Senthikumara Nadar College, Virudhunagar, Tamil Nadu, India
2Associate Professor, Research centre in Computer Science, V.H.N. Senthikumara Nadar College, Virudhunagar, Tamil Nadu, India
*Corresponding Author
Email: [email protected]
Received Date:20 January 2023, Accepted Date:29 March 2023, Published Date:24 April 2023
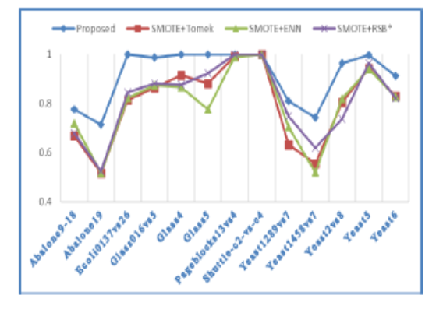
Objective: The traditional classifiers are ineffective in classifying the imbalanced datasets. Most popular approach in resolving this problem is through data re-sampling. A hybrid resampling method is proposed in this paper that reduces the misclassification in all the classes. Method: The proposed method employs the Leader algorithm for under sampling and SMOTE algorithm for oversampling. It generates the desired number of samples in both the classes based on the problem that overcomes the over-fitting and under-fitting issues. Findings: To evaluate the performance of the proposed work, it is tested on 13 high imbalanced datasets obtained from the keel repository and the results are compared with the state-of-the-art hybrid data resampling methods such as SMOTE+Tomek Links, SMOTE+ENN, and SMOTE+RSB*. From the experiment it is observed that among the 13 high imbalanced datasets, the proposed method outperforms in 12 datasets and produces the same result in 1 dataset. The proposed method reduces the misclassification rates of minority and majority classes and is more suitable for the extreme imbalanced datasets. Novelty: This research work introduces a novel approach for classification by combining machine learning algorithms with domain-specific knowledge and resulting in significantly improved accuracy in classifying the extreme imbalanced datasets compared to the traditional methods. The uniqueness of the work is the utilization of the Leader algorithm and the SMOTE algorithm with a required resampling ratio instead of balancing and it improves the performance of the classification on the imbalanced data.
Keywords: Imbalanced Data; Leader; SMOTE; Hybrid Sampling; Resampling; Classification
© 2023 Karthikeyan & Kathirvalavakumar. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.




