Indian Journal of Science and Technology
DOI: 10.17485/IJST/v16i29.1500
Year: 2023, Volume: 16, Issue: 29, Pages: 2261-2268
Original Article
Navin Kumar Goyal1*, Anil Pal2, Bright Keswani3, Dinesh Goyal4, Mukesh Kr Gupta5
1Research Scholar, Department of Computer Engineering and Information Technology, Suresh Gyan Vihar University, Jaipur, Rajasthan, India
2Professor, Department of Computer Application, Suresh Gyan Vihar University, Jaipur, Rajasthan, India
3Professor, Department of Computer Application, Poornima University, Jaipur, Rajasthan, India
4Director, Poornima Institute of Engineering and Technology, Jaipur, 302022, Rajasthan, India
5Professor, Department of Electrical Engineering, Suresh Gyan Vihar University, Jaipur, Rajasthan, India
*Corresponding Author
Email: [email protected]
Received Date:19 June 2023, Accepted Date:28 June 2023, Published Date:05 August 2023
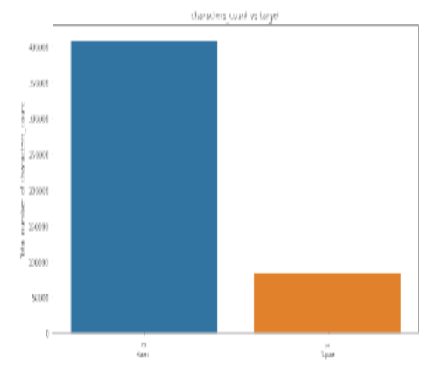
Objectives: To develop a novel hybrid method for feature generation and a novel dataset for experimenting and extracting the features for numerical representation. Methods: In the pursuit of the best spam review detection model, a four-stage process was undertaken. Initially, a dataset ‘Fake reviews’ was collected from Flipkart, containing 9926 samples from the home and kitchen products domain. Next, the data underwent pre-processing using the Natural Language Toolkit (NLTK) library. A novel Hybrid Feature Generator (HFG) was then developed, extracting informative features based on parameters like TF-IDF (Term Frequency - Inverse Document Frequency), sentiment analysis scores, and syntactic patterns. Finally, the model was trained on these generated features using Gaussian Naïve Bayes (GNB), Multinomial Naïve Bayes (MNB), and Bernoulli Naïve Bayes (BNB) algorithms. Performance evaluation was conducted using metrics such as accuracy, precision, recall, and F1-score, comparing the model’s results to gold standard or known spam reviews. Findings: The feature generation technique was implemented on three different models, and the models were trained using 70% of the available data. The results of these experiments showed that GNB, NB, and NB achieved testing accuracies of 99.7%, 96.4%, and 99%, respectively. The performance of these models was compared with and without the inclusion of extracted product review features. The results demonstrated that the GNB algorithm outperformed the other methods in terms of accuracy and precision. Novelty: This study presents a novel HFG for feature extraction from review-text and a novel dataset that outperforms hitherto reportedapproaches.
Keywords: Fake Reviews Detection; Ensemble Machine Learning; Feature Engineering; Naïve Bayes; Web Scrapping
© 2023 Goyal et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.