Indian Journal of Science and Technology
Year: 2024, Volume: 17, Issue: 15, Pages: 1515-1526
Original Article
G Shimi1, C Jerin Mahibha2*, Durairaj Thenmozhi3
1Department of Computer Applications, Madras Christian College, Tambaram, Chennai, 600059, Tamil Nadu, India
2Department of Computer Science and Engineering, Meenakshi Sundararajan Engineering College, Kodambakkam, Chennai, 600 024, Tamil Nadu, India
3Department of Computer Science and Engineering, Sri Sivasubramaniya Nadar College of Engineering, Kalavakkam, 603 110, Tamil Nadu, India
*Corresponding Author
Email: [email protected]
Received Date:01 April 2023, Accepted Date:13 March 2024, Published Date:04 April 2024
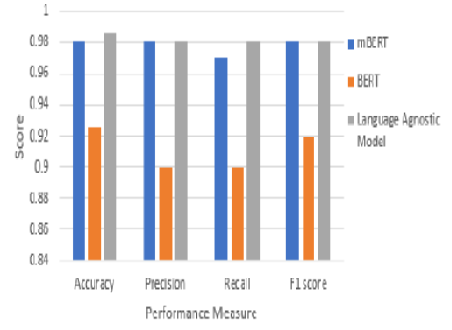
Objectives: Language detection is the process of identifying a language associated with a text. The proposed system aims to detect the Dravidian language that is associated with the given text using different machine learning and deep learning algorithms. The paper presents an empirical analysis of the results obtained using the different models. It also aims to evaluate the performance of a language agnostic model for the purpose of language detection. Method: An empirical analysis of Dravidian language identification in social media text using machine learning and deep learning approaches with k-fold cross validation has been implemented. The identification of Dravidian languages, including Tamil, Malayalam, Tamil Code Mix, and Malayalam Code Mix, is performed using both machine learning (ML) and deep learning algorithms. The machine learning algorithms used for language detection are Naive Bayes (NB), Multinomial Logistic Regression (MLR), Support Vector Machine (SVM), and Random Forest (RF). The supervised Deep Learning (DL) models used include BERT, mBERT and language agnostic models. Findings: The language agnostic model outperform all other models considering the task of language detection in Dravidian languages. The results of both the ML and DL models are analyzed empirically with performance measures like accuracy, precision, recall, and f1-score. The accuracy associated with different machine learning algorithms varies from 85% to 89%. It is evident from the experimental result that the deep learning model outperformed with an accuracy of 98%. Novelty: The proposed system emphasizes on the use of the language agnostic model to implement the process of detecting Dravidian languages associated with the given text which provides a promising result of 98% accuracy which is higher than the existing methodologies.
Keywords: Language, Machine learning, Deep learning, Transformer model, Encoder, Decoder
© 2024 Shimi et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.