Indian Journal of Science and Technology
DOI: 10.17485/IJST/v13i40.1451
Year: 2020, Volume: 13, Issue: 40, Pages: 4216-4224
Original Article
Neha Garg1∗, Kamlesh Sharma2
1 Assistant Professor, Department of Computer Science & Engineering, Manav Rachna International Institute of Research & Studies, Faridabad, Haryana, India.
2 Associate Professor, Department of Computer Science & Engineering, Manav Rachna International Institute of Research & Studies, Faridabad, Haryana, India.
∗ Corresponding author:
Tel: +91- 8882879289
[email protected]
Received Date:26 September 2020, Accepted Date:08 November 2020, Published Date:20 November 2020
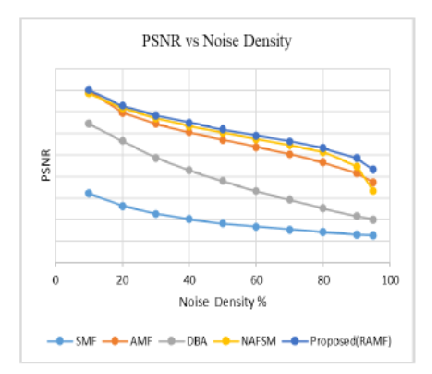
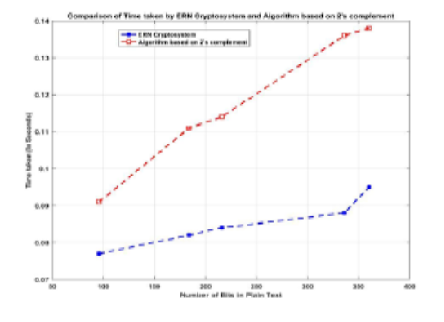
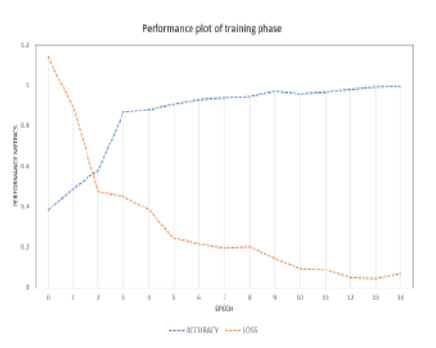
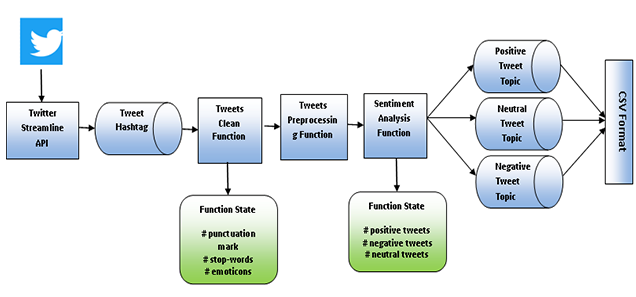
Background: Evaluating the sentiments of tweets, blogs, comments and posts have become a crucial part of many applications. Sentiment analysis of social network data is very helpful for decision-making in application areas like movie reviews, product feedback and impact of the speech of a politician etc. The users often comment in their native languages or in slang languages or more often they use abbreviations and do not even stick to grammatical rules of the language. The bilingual and multilingual community often mixes two or more than two languages in their comments. Unavailability of annotated code-mixed data for native language adds to the difficulty in performing sentiment analysis. Objectives: The motive of this article is to present the process of creating annotated corpus for code mixed social media text in Hindi, English and Hinglish which is collected from twitter. Ambiguous meaning words and inconsistent spellings of both the languages have also been included in the study to provide wide spread canvas. Method: This study will provide significant elements that should be considered while developing the annotated corpus of Hindi, Hinglish & English dataset. The annotation is calculated on the basis of polarity of words in three categories as positive, negative and neutral. There are words which have mixed feeling i.e. these words have positive as well as negative sentiments. To consider these words, inner agreement among the polarities has been considered. The words used for sarcasm or slangs have also been taken into account. The study has included ambiguous meaning and inconsistent spelling words of both languages as well. Findings: The proposed work provides a standard annotated corpus for code switched social media text in Hindi-English (Hinglish). The process of developing the corpus and calculating the polarity has been shown. It is found that if one considers the code-mixed text, the accuracy can be enhanced. Application: The proposed corpus can be utilized in the area of market analysis, customer behavior, polling analysis, brand monitoring, etc. The corpus serves as dataset which can further be extended according to the problem definition.
Keywords: Machine learning; sentiment analysis; data preprocessing; data cleaning; code-switch; linguistic-switching; multilingual
© 2020 Garg & Sharma. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee).
Subscribe now for latest articles and news.