Indian Journal of Science and Technology
DOI: 10.17485/ijst/2016/v9i37/85826
Year: 2016, Volume: 9, Issue: 37, Pages: 1-5
Original Article
Adeel Shiraz Hashmi* and Tanvir Ahmad
Department of Computer Engineering, Jamia Millia Islamia, Delhi, India; [email protected]
*Author for correspondence
Adeel Shiraz Hashmi
Department of Computer Engineering
Email: [email protected]
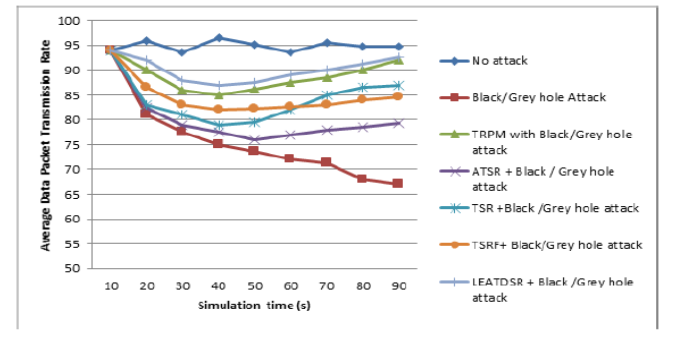
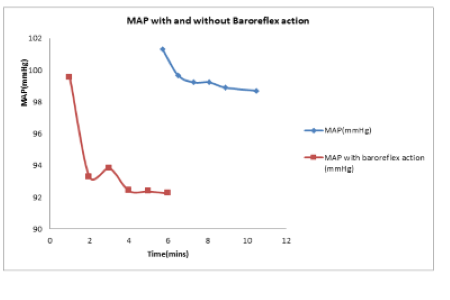
Objectives: The objective of this research work is to discuss the various techniques which can be used for mining of big data viz. sampling, incremental learning, and distributed learning. Methods: For this study, literature survey was done to identify the various techniques employed by different authors to handle large (and streaming) data sets. For each technique, one or more algorithm was chosen and applied on large data sets. The platform for each technique was standardized (R libraries were used for each algorithm). The algorithms were compared on accuracy and time-consumed. Findings: The findings of this research work which conform to the existing literature is that the distributed learning is the best approach in terms of accuracy and time-complexity, for large data sets. However, if the data sets are streaming data sets and we want to perform real-time analysis then sampling or incremental approach are better than distributed approach. Incremental approach provides better accuracy, whereas sampling reduces time-complexity. Novelty: This study is important in the sense that it brings all the three techniques together on a single platform, which hasn’t been done earlier.
Keywords: Big Data, Data Mining, Distributed Learning, Incremental Learning, Sampling
Subscribe now for latest articles and news.