Indian Journal of Science and Technology
DOI: 10.17485/IJST/v14i30.1030
Year: 2021, Volume: 14, Issue: 30, Pages: 2460-2471
Original Article
Phan Bui Khoi1*, Nguyen Truong Giang1, Hoang Van Tan1
1School of Mechanical Engineering, Hanoi University of Science and Technology, 01 Dai Co
Viet, Hai Ba Trung, Hanoi, 100000, Vietnam
*Corresponding Author
Email: [email protected]
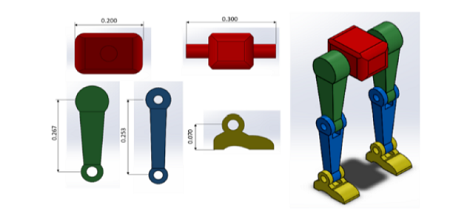
Objectives: To study an algorithm to control a bipedal robot to walk so that it has a gait close to that of a human. It is known that the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm is a highly efficient algorithm with a few changes compared to the popular algorithm — the commonly used Deep Deterministic Policy Gradient (DDPG) in the continuous action space problem in Reinforcement Learning. Methods: Different from the usual sparse reward function model used, in this study, a reward model combined with a sparse reward function and dense reward function will be proposed. The application of the TD3 algorithm together with the proposed reward function model to control a bipedal robot model with 6 degrees of freedom will be presented. The training process is simulated in Gazebo/Robot Operating System (ROS) environment. Finding: The results show that, when choosing a reward model combined with a sparse reward function and a dense reward function suitable for the robot model, will help it learn faster and achieve better results. The biped robot can walk straight with an almost human-like gait. In the paper, the results from the TD3 algorithm combined with the proposed reward model are also compared with the results from other algorithms. Novelty: Applying the TD3 algorithm combined with the proposed reward model for the 6-DOF biped robot and simulating the robot’s gait in Gazebo/ROS environment, ROS is a middleware that can be used to control a robot in a real environment in the future.
Keywords: TD3; biped robot; reinforcement learning; ROS; Gazebo
© 2021 Khoi et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.




