Indian Journal of Science and Technology
Year: 2022, Volume: 15, Issue: 1, Pages: 9-18
Original Article
Anna Fay E Naïve1, Jocelyn B Barbosa2*
1Instructor, Department of Information Technology, University of Science and Technology of
Southern Philippines, C.M Recto Ave., Lapasan, Cagayan de Oro City, 9000, Philippines
2Associate Professor, Department of Information Technology, University of Science and
Technology of Southern Philippines, C.M Recto Ave., Lapasan, Cagayan de Oro City, 9000, Philippines
*Corresponding Author
Email: [email protected]
Received Date:10 December 2021, Accepted Date:30 December 2021, Published Date:21 January 2022
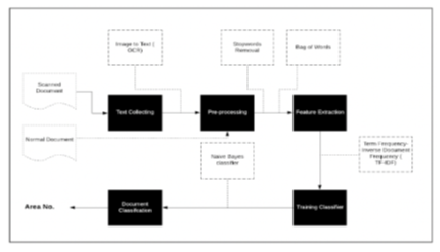
Objectives: To develop a desktop application that automatically classifies a document as to which area of accreditation documents it should belong to. Specifically, it aims to: a) To create a predictive model that addresses document classification tasks. b) To design and develop an application that classifies documents according to document classification. c) To evaluate the performance measures of the automatic document classification. Methods: We introduce an innovative approach for the automatic classification of accreditation documents. Specifically, an approach of including scanned or captured documents in classification task using Optical Character Recognition (OCR); use TFIDF (Term-frequency Inverse Document Frequency) with stopwords removal, ngram of 1-2 in preprocessing of the text documents; and Naive Bayes algorithm with additive (Laplace/Lidstone) smoothing as a classifier in building our model. Results: Performance measures such as accuracy, precision, recall, and f-score were conducted to evaluate the efficiency of the study. The results showed 82% accuracy, 84% precision, 82% recall, and 82% F-1 score. As we explore the use of OCR for text extraction, TF-IDF for text preprocessing, and Naive Bayes classifier, the results indicate that the proposed approach is efficient. Conclusions: Classification of input documents in whatever forms, may it be captured image, scanned or simple text documents were obtained using OCR, TF-IDF, and Naive Bayes classifier. It provides an efficient way of automatic classification of accreditation documents and it gives an avenue to address limiting factors of the previous works, i.e classifying documents based on one’s opinion and time-consuming classification.
Keywords: Accreditation Document Classification; Document Classification Objective Evaluation; TF-IDF; Term frequency-inverse document frequency; Multinomial Naive Bayes; OCR; Optical Character Recognition
© 2022 Naïve & Barbosa. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.




