Indian Journal of Science and Technology
DOI: 10.17485/ijst/2016/v9i38/101792
Year: 2016, Volume: 9, Issue: 38, Pages: 1-5
Original Article
S. Rajeswari1*, M. S. Josephine2 and V. Jeyabalaraja3
1 Bharathiyar University, Coimbatore - 641046, India; [email protected]
2 Dr. M.G.R. Educational and Research Institute, Chennai - 600095, India; [email protected]
3 Velammal Engineering College, Chennai - 600066, India; [email protected]
*Author for correspondence
Rajeswari
Bharathiyar University
Email:[email protected]
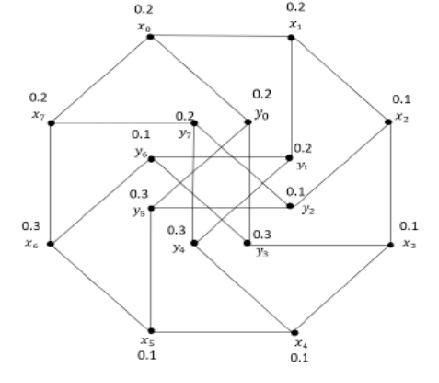
Objectives: Heterogeneous High dimensional data clustering is the analysis of data with multiple dimensions. Large dimensions are not easy to handle. The complexity increases exponentially with the dimensionality. Dimensionality reduction is the conversion of high dimensional data into a considerable representation of reduced dimensionality that corresponds to the essential dimensionality of the data. To solve the problem we put forward a general framework for clustering high dimensional datasets. Methods: Clustering is the method of finding groups of objects, such that the objects in the group will be similar to each another and different from the objects in other groups. In our framework, a heterogeneous high dimensional clustering is partitioned into several one or two dimensional clustering phases. Findings: In this paper, a model is designed in which Hierarchical-Divisive clustering; subspace clustering is used to make non-overlapping clusters and combined with dimension reduction techniques to reduce the dimensions of paradoxical high dimensional clinical datasets. Applications: solution for processing the heterogeneous high dimensional dataset such as PCA, LDA, and PSO etc.
Keywords: High Dimensional Data, Hierarchical-Divisive (H-D) Clustering, Subspace Clustering
Subscribe now for latest articles and news.