Indian Journal of Science and Technology
Year: 2020, Volume: 13, Issue: 19, Pages: 1890-1900
Original Article
M Ameen Chhajro1∗, Mansoor Ahmed Khuhro1 , Kamlesh Kumar1 , Asif Ali Wagan1 , Aamir Iqbal Umrani1 , Asif Ali Laghari1
1 Department of Computer Science, Sindh Madressatul Islam University, Karachi, Pakistan
∗Corresponding author:
M Ameen Chhajro
Department of Computer Science, Sindh Madressatul Islam University, Karachi, Pakistan
Email: [email protected]
Received Date:11 April 2020, Accepted Date:17 May 2020, Published Date:18 June 2020
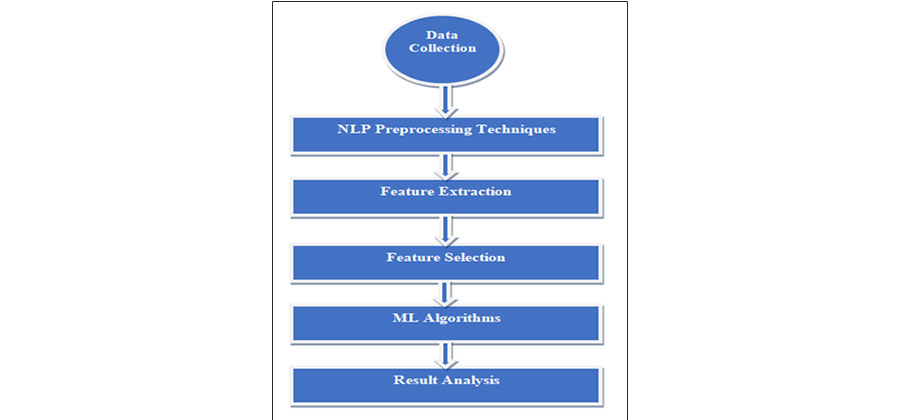
Objectives: This research presents multi-text classification from the news text dataset. The main purpose of this work is to classify multi-text for Urdu and Roman language using Natural Language processing and Machine Learning classification models. Methods/Statistical analysis: In this research, online news data has been collected through beautiful soup web scraping tool. In order to analyze the model accuracy news data is divided into six categories which has been composed from various online newspaper platforms. The main news corpus data consists of 10500 news in Urdu and Roman Urdu language including, Accidental, Education, Entertainment, International, Sports and Weather news have been primarily focused in the proposed research study. Furthermore, preprocessing is performed on text corpus using Natural Language Processing technique; for example, data cleaning, data balancing, and stop word removal. For feature extraction count vector, TF-IDF and Chi2 are employed as word filtering. For multi-text classification the Machine Learning classification schemes have been implemented namely, Naive Bayes Classifier, Logistic Regression, Random Forest Classifier, Linear SVC, and KNeighbors Classifier. After comparative analysis results showed that Linear Support Vector Classifier provided 96% accuracy among other tested methods. Findings: Multi-Text classification of Urdu Roman language having different writing styles, word structure, irregularities, grammar, and combined corpus is a challenging task. For this purpose, we implemented different Machine Learning algorithms with Natural Language preprocessing technique which provided optimal results in classification of multi-text news data.
Keywords: MultiText Classification; Machine Learning; NLP Preprocessing Techniques
© 2020 Chhajro, Khuhro, Kumar, Wagan, Umrani, Laghari. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.