Indian Journal of Science and Technology
DOI: 10.17485/ijst/2016/v9i39/100777
Year: 2016, Volume: 9, Issue: 39, Pages: 1-6
Original Article
Mohammed Abdul Wajeed*
Computer Science and Engineering Department, Jyothi Engineering College, Cheruthuruthy - 679531, Kerala, India; [email protected]
*Author for correspondence
Mohammed Abdul Wajeed
Computer Science and Engineering Department
Email:[email protected]
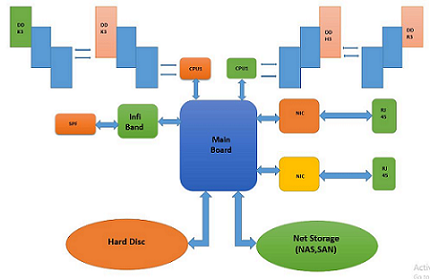
Text class has loved its privilege as a core studies area in text mining. Supervised, unsupervised are the 2 famous paradigms within the technique of type. Relatively novel method of classification is semi-supervised mastering which is midway among the supervised and unsupervised getting to know. With smaller schooling statistics units and taking the large without problems to be had unlabeled data, the procedure of studying in class is refined. There are versions in semisupervised, transductive gaining knowledge of wherein the trained and untrained facts are given in advance the classifier is built, the goal is to expect the magnificence label of untrained data. The opposite version is inductive learning in which the labeled and unlabeled statistics is utilized in model constructing; goal of the version is to predict the unseen information magnificence label. The paper aims to using transductive getting to know to classifying the textual statistics with the aid of considering the phrases appearing in special parts of the record. The words performing inside the introductory and conclusion a part of the files may additionally play important function within the procedure of type, than the ones seemed in other parts. The approach employed could provide one of a kind weights to words primarily based on their presence in one-of-a-kind role of the document. Taking into consideration the above within the procedure of mapping the textual facts into numerical patterns editions of distributed vector generations are acquired. Taking into account large differences in the duration of the documents, distinct normalization techniques are employed which gave eights one-of-a-kind vectors. Non-parametric, most effective to put into effect ok-nearest neighbour algorithm is hired for free-go with the flow textual classification. The outcomes received conclude that semi-supervised textual class can be carried out without loss in category accuracy where restrained skilled records is to be had, as the accuracies of the gaining knowledge of model in supervised and emi-supervised coincide with each other.
Keywords: Distributional Vectors, KNN, Semi-Supervised, Text Classification, Transductive Learning
Subscribe now for latest articles and news.