Indian Journal of Science and Technology
DOI: 10.17485/ijst/2017/v10i6/110837
Year: 2017, Volume: 10, Issue: 6, Pages: 1-6
Original Article
T. Siva Sankara Phani1 , B. Ananda Krishna2 and Ranjan K. Senapati1
1Department of ECE, KL University, Green Fields, Vaddeswaram, Guntur – 522502, Andhra Pradesh, India, [email protected], [email protected] 2Department of ECE, Guntur Engineering College, NH 5, Opposite Katuri Medical College, Yanamadala, Guntur - 522019, Andhra Pradesh, India; [email protected]
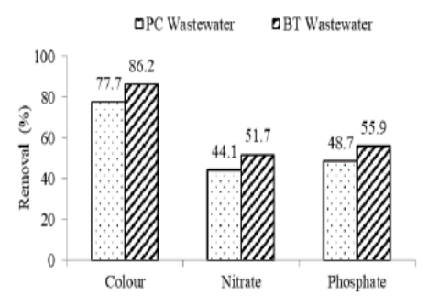
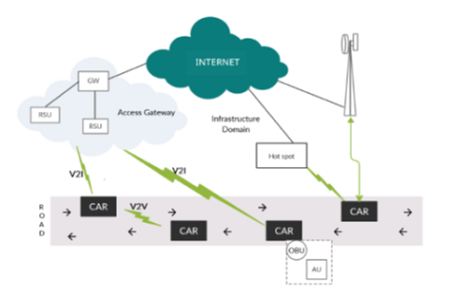
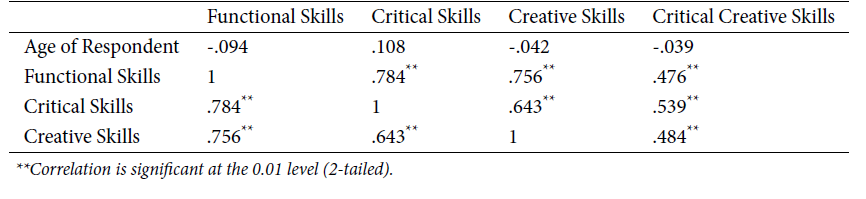
Objectives: In previous methodology, only ALU operations are seen with respect to the network on chip with this power and delay is high whereas in present research, Multi-grained reconfigurable architecture is used which reduces power and delay. In this method we can also perform multiple FFT, DCT, FIR and channel encoder. Methods: For execution, the number of instructions is flapped by associating pipelining technique which is splitted in stages. Every stage completes an area of parallely connected instructions at a time. A pope is created, with the interconnection of stages where instructions are fed at amend, progresses through these stages and exits at other end. The group of Function Units (FU’S) was connected in a mesh style network in CGRA’S. Here, the subsets of FU’s are accessed only with help of segregation of register files through CGRA’s that which carries temporary values. In general word operations like addition, subtraction and multiplication were carried out by these function units. Findings: For better execution characteristics of parallel mapping on MGRA, more PE utilisation rate and less memory access overhead are considered as resulting conditions. Lastly, Multi Grained Reconfigurable Architecture (MGRA) is the proposed research work where processing element consists of a multiple operations like FFT, DCT, FIR, Channel Encoder etc. The proposed architectures require multiple processing elements to execute parallel process as to reduce PE’s complexity. A new folding tree algorithm is proposed (MGRA) with CRGA is proposed to eliminate PE’s. This method reutilizes PE’s to redistribute data from multiple nodes and the controller is integrated with current CGRA to scan the processing nodes with common expression executions. By using nested loop pipelining the Multi grained reconfigurable architecture comprises the advantages of low power and delay when compared to the existing architectures. Application: MGRA used in communication, digital signal processing
Keywords: CGRA, Multi-GrainedReconfigurableArchitecture (MGRA),Network-on-Chip, Parallel Mapping,Reconfigurable Computing
Subscribe now for latest articles and news.