Indian Journal of Science and Technology
Year: 2022, Volume: 15, Issue: 8, Pages: 333-342
Original Article
Praveen Kumar1*, H S Jayanna2
1Research Scholar, Department of ECE, Siddaganga Institute of Technology, Tumakuru, 572103, Karnataka, India
2Department of ISE, Siddaganga Institute of Technology, Tumakuru, 572103, Karnataka, India
*Corresponding Author
Email: [email protected]
Received Date:12 November 2021, Accepted Date:22 January 2022, Published Date:02 March 2022
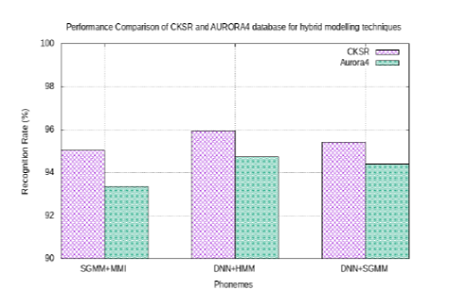
Objectives: The primary goal is to address attempts to establish a Continuous Speech Recognition (CSR) framework for recognising continuous speech in Kannada. It is a difficult challenge to deal with a local language such as Kannada, which lacks the resources of a single language database. Methods: Modelling techniques such as monophone, triphone, deep neural network (DNN)-hidden Markov model (HMM) and Gaussian Mixture Model (GMM)- HMM-based models were implemented in Kaldi toolkit and used for continuous Kannada speech recognition (CKSR). To extract feature vectors from speech data, the Mel frequency Cepstral (MFCC) coefficient technique is used. The continuous Kannada speech database consists of 2800 speakers (1680 males and 1120 females) belong to the age group 8 years to 80 years. The training and testing data are in the ratio 80:20. In this paper the hybrid modelling techniques are implemented to recognize the spoken words. Findings: The model efficiency is determined based on the word error rate (WER) and the obtained results are assessed with the well-known datasets such as TIMIT and Aurora-4. This study found that using Kaldi-based features ex- traction recipes for monophone, triphone, DNN-HMM and GMM-HMM acoustic models had a word error rate (WER) of 8.23%, 5.23%, 4.05% and 4.64% respectively. The experimental results suggest that the rate of recognition of Kannada speech data has increased higher than that of state-of-the-art databases. Novelty : We propose a novel automatic speech recognition system for Kannada language. The main reason for developing the automatic speech recognition system for Kannada language is that there are only limited sources of standard continuous Kannada speech are available. We created large vocabulary Kannada database. We implemented monophone, triphone, Subspace Gaussian mixture model (SGMM) and hybrid modelling techniques to develop the automatic speech recognition system for Kannada language.
Keywords: DNN; Continuous speech; HMM; Kannada dialect; Kaldi toolkit; monophone; triphone; WER
© 2022 Kumar & Jayanna. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Published By Indian Society for Education and Environment (iSee)
Subscribe now for latest articles and news.




