Indian Journal of Science and Technology
DOI: 10.17485/ijst/2017/v10i11/89318
Year: 2017, Volume: 10, Issue: 11, Pages: 1-10
Original Article
G. Asha Kiran1*, Manimala Puri2 and S. Srinivasa Suresh3
1MBA Department, Rajarshri Shahu College of Engineering, Survey No.80, Pune-Mumbai Bypass Highway, Tathawade, Pune - 411033, Maharashtra, India; [email protected] 2JSPM Group of Institutes, Survey No.80, Pune-Mumbai Bypass Highway, Tathawade, Pune - 411033, Maharashtra, India; [email protected] 3CSE Department, KMIT, 3-5-1026, Narayanguda, Hyderabad - 500029, Telangana, India; [email protected]
*Author for correspondence
G. Asha Kiran
MBA Department, Rajarshri Shahu College of Engineering, Survey No.80, Pune-Mumbai Bypass Highway, Tathawade, Pune - 411033, Maharashtra, India; [email protected]
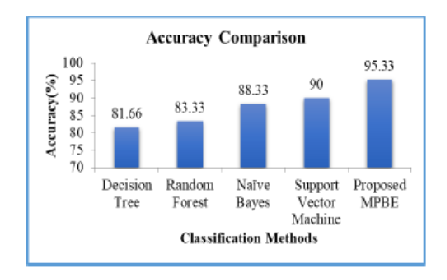
Background/Objective: Privacy is the vital issue when sharing of the data comes into picture. The demand and scope for privacy is increasing day-by-day as data storage techniques have emerged from standalone database to distributed database and then progressed to parallel databases. K-means and Fuzzy C-means (FCM) are the frequently used clustering algorithms for standalone database, distributed database and parallel databases. The current paper highlights Particle Swam Optimization algorithm along with Fuzzy C-means clustering algorithm technique for preserving the privacy on distributed databases. Methods/Statistics Analysis: The experimentation is performed by means of the datasets accessible in the UCI machine-learning repository. The main benefit of the suggested technique is that, this technique will assess in terms of their privacy of cluster. Therefore, the technique plans to give improved visibility for the protected data. The technique is executed in the working platform of MATLAB and the effects will be examined to show the presentation of the suggested clustering technique. Findings: The performance of the proposed clustering technique based on privacy preserving is analyzed for accuracy and Database Different Ratio (DBDR) on six UCI medical related data sets namely Hugerian dataset, Cleveland data set, Reprocessed Hugerian data sets, Long Beach V.A data, BUPA and liver disorder data. Performance improvement observed in the range of 3%-6% on each of the six data sets compared to K-means algorithm. Application/Implementation: The main benefit of the suggested technique is that technique will have to assess in terms of their privacy of cluster. Therefore, the technique plans to give improved visibility for the protected data.
Keyword: Clustering, Distributed Data, K-means, PPSSI, PSO
Subscribe now for latest articles and news.